Notes on "Deep Learning Bookcamp"
Table of Contents
1 Introduction
2 Chapter 2: Predicting car prices
2.1 Exercises and code
2.1.1 Utility functions
Convert the code from chapter 2 to a set of functions:
import numbers import pandas as pd import numpy as np
Read the data and clean up the column names / alphanumeric data:
def read_data(file): """Read a dataframe from a CSV file. Parameters: file (string): path to a CSV file. Returns: DataFrame holding the contents of the file. """ df = pd.read_csv(file) return df def clean_alphanum_data(df): """Clean up alphanumeric data in a dataframe. Convert all strings to lower case and replace spaces with underscores. Parameters: df (DataFrame): the dataframe to be cleaned. Returns: None. """ df.columns = df.columns.str.lower().str.replace(' ', '_') string_columns = list(df.dtypes[df.dtypes == 'object'].index) for col in string_columns: df[col] = df[col].str.lower().str.replace(' ', '_')
Split the data frame into a train, validation and test set:
def split_data_frame(df, split=0.2, seed=None): """Split a dataframe into a train, validation and test set. The dataframe is first randomized and then split into three parts. Parameters: df (DataFrame): the dataframe to split. split (float): fraction of the dataframe to use for validation and test sets. seed (int): the seed used for randomization. Returns: 3-tuple of DataFrame, DataFrame, DataFrame (train, validation, test). """ n = len(df) n_val = int(split * n) n_test = int(split * n) n_train = n - (n_val + n_test) idx = np.arange(n) if isinstance(seed, numbers.Number): np.random.seed(seed) np.random.shuffle(idx) df_shuffled = df.iloc[idx] df_train = df_shuffled.iloc[:n_train].copy() df_val = df_shuffled.iloc[n_train:n_train+n_val].copy() df_test = df_shuffled.iloc[n_train+n_val:].copy() return df_train, df_val, df_test
Prepare the data. I add two arguments to prepare_X: base, which is a list of
the features in the dataframe that should be used, and fns, a list of
functions to extract additional features.
def prepare_X(df, base, fns=[]): """Prepare a dataframe for learning. Convert the dataframe to a Numpy array: - Extract the features in `base`. - Apply the functions in `fns` to the dataframe to derive new features from existing ones (e.g., for binary encoding). The elements of `fns` should be lists `(fn, arg, arg, arg, ...)`. Before calling each function, `df` is prepended to the list of arguments. The functions should add the new features to `df`, and they should return a list of the names of the new feature(s) as strings. - Fill any missing data with 0. Note that `df` is not modified. The functions in `fns` should modify their dataframe argument, but they operate on a copy of `df`. Parameters: df (DataFrame): dataframe to convert. base (list of strings): list of fields in the dataframe to be used for the array. fns (list of tuples (function, arg list)): feature engineering functions. Returns: ndarray of the prepared data. """ df = df.copy() features = base.copy() for fn, *args in fns: args = [df] + args new_features = fn(*args) # Note: `fn` should also modify the local copy of `df`! features += new_features df_num = df[features] df_num = df_num.fillna(0) X = df_num.values return X
Two functions for feature engineering:
def binary_encode(df, feature, n=5): """Binary encode a categorical feature. Take the top `n` values of `feature` and add features to `df` to binary encode `feature`. The dataframe is modified in place. Parameters: df (DataFrame): the dataframe to add the feature to. feature (string): feature in df to be binary encoded. n (int): number of values for feature to encode. Returns: List of new features. """ assert feature in df top_values = df[feature].value_counts().head(n) new_features = [] for v in top_values.keys(): binary_feature = feature + '_%s' % v df[binary_feature] = (df[feature] == v).astype(int) new_features.append(binary_feature) return new_features def encode_age(df, year_field, current_year): """Encode the age of an item as a feature. The age is calculated on the basis of the contents of `year_field` and `current_year`. Parameters: df (DataFrame): dataframe to encode the age in. year_feature (string): the feature that encodes the relevant year. current_year (int): the year used to calculate the age. Returns: Constant value ['age']. """ assert year_field in df assert df[year_field].dtype == 'int64' df['age'] = current_year - df[year_field] return ['age']
binary_encode can be generalized to a function that loops over a list of
features:
def binary_encodes(df, features, n=5): """Binary encode a list of features. Each feature is passed to `binary_encode`. See there for details. Note that `df` is modified in place. Parameters: df (DataFrame): the dataframe to engineer features from. features (list of strings): list of features to binary encode. n (int): number of values for feature to encode. Returns: A list of features added to `df`. """ all_new_features = [] for feature in features: new_features = binary_encode(df, feature, n) all_new_features += new_features return all_new_features
The linear_regression and rmse functions. These weren't modified:
def linear_regression(X, y, r=0.0): """Perform linear regression. Parameters: X (ndarray): array of input values. y (ndarray): target values. r (float): regularization amount. Returns: Tuple of float, ndarray (bias, array of weights) """ ones = np.ones(X.shape[0]) X = np.column_stack([ones, X]) XTX = X.T.dot(X) reg = r * np.eye(XTX.shape[0]) XTX = XTX + reg XTX_inv = np.linalg.inv(XTX) w = XTX_inv.dot(X.T).dot(y) return w[0], w[1:] def rmse(y, y_pred): """Compute the root mean square error. Parameters: y (ndarray): target values. y_pred (ndarray): predicted values. Returns: float """ error = y_pred - y mse = (error ** 2).mean() return np.sqrt(mse)
2.1.2 Car prices
The goal is to see if more feature engineering improves the model. The RMSE of the model as developed in chapter 2 is 0.46. Can this be improved?
Let us set up the model. First, read the data and clean it up:
df = read_data('../data/cars.csv') clean_alphanum_data(df) df.head()
make model year engine_fuel_type engine_hp engine_cylinders transmission_type ... market_category vehicle_size vehicle_style highway_mpg city_mpg popularity msrp 0 bmw 1_series_m 2011 premium_unleaded_(required) 335.0 6.0 manual ... factory_tuner,luxury,high-performance compact coupe 26 19 3916 46135 1 bmw 1_series 2011 premium_unleaded_(required) 300.0 6.0 manual ... luxury,performance compact convertible 28 19 3916 40650 2 bmw 1_series 2011 premium_unleaded_(required) 300.0 6.0 manual ... luxury,high-performance compact coupe 28 20 3916 36350 3 bmw 1_series 2011 premium_unleaded_(required) 230.0 6.0 manual ... luxury,performance compact coupe 28 18 3916 29450 4 bmw 1_series 2011 premium_unleaded_(required) 230.0 6.0 manual ... luxury compact convertible 28 18 3916 34500 [5 rows x 16 columns]
Split the data set into a train, validation and test set:
df_train, df_val, df_test = split_data_frame(df, split=0.2, seed=2) y_train = np.log1p(df_train.msrp.values) y_val = np.log1p(df_val.msrp.values) y_test = np.log1p(df_test.msrp.values)
Remove the target value ("msrp" or "manufacturer's suggested retail price") from the data set:
del df_train['msrp'] del df_val['msrp'] del df_test['msrp']
Prepare the data. To confirm the results in the book (and make sure my code is working), I'll first use the same parameters:
# Prepare the training data. base = ['engine_hp', 'engine_cylinders', 'highway_mpg', 'city_mpg', 'popularity'] fns = [[encode_age, 'year', 2017], [binary_encodes, ["number_of_doors", "make", "engine_fuel_type", "transmission_type", "driven_wheels", "market_category", "vehicle_size", "vehicle_style"], 5]] X_train = prepare_X(df_train, base, fns)
Now train the model:
w_0, w = linear_regression(X_train, y_train, 0.01)
If we apply the model to the training data, we should get the original prices again. In reality, we don't.
from matplotlib import pyplot as plt import seaborn as sns
y_pred = w_0 + X_train.dot(w) plt.clf() sns.histplot(y_pred, label='pred') sns.histplot(y_train, label='y', color='red') plt.legend() plt.savefig('figures/figure2-06.png') 'figures/figure2-06.png'
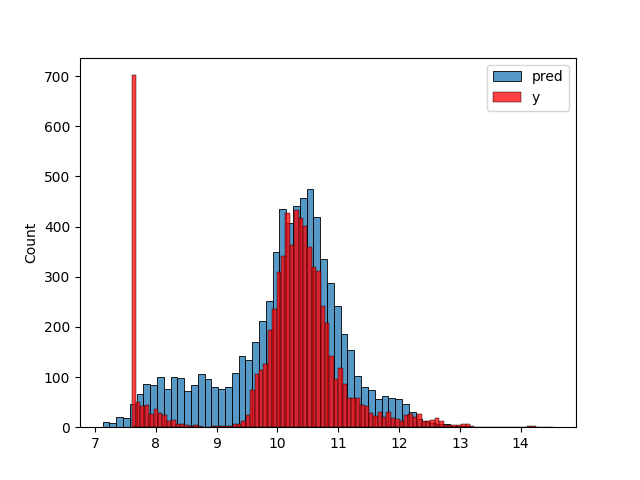
We can compute the RMSE for the model:
rmse(y_train, y_pred)
0.46020995201980425
We should of course compute the RMSE on the validation set:
X_val = prepare_X(df_val, base, fns) y_pred = w_0 + X_val.dot(w) rmse(y_val, y_pred)
0.476510145790575
Let's follow the suggestion in exercise 2.5.1 and include more values in the binary encoded features:
fns = [[encode_age, 'year', 2017], [binary_encodes, ["number_of_doors", "make", "engine_fuel_type", "transmission_type", "driven_wheels", "market_category", "vehicle_size", "vehicle_style"], 8]] X_train = prepare_X(df_train, base, fns) w_0, w = linear_regression(X_train, y_train, 0.01) y_pred = w_0 + X_train.dot(w) plt.clf() sns.histplot(y_pred, label='pred') sns.histplot(y_train, label='y', color='red') plt.legend() plt.savefig('figures/figure2-07.png') 'figures/figure2-07.png'
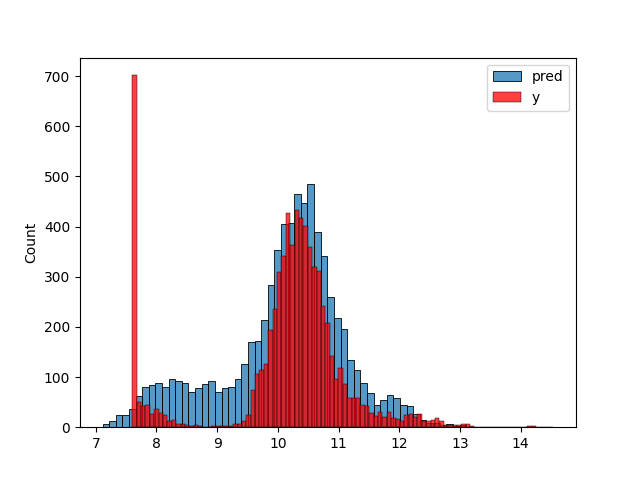
Evaluating against the validation set:
X_val = prepare_X(df_val, base, fns) y_pred = w_0 + X_val.dot(w) rmse(y_val, y_pred)
0.4850113357947244
The performance seems to have degraded, not improved, although only by a little.
Note that trying to use 10 values for binary encoding fails, because the validation set then gains an extra feature. The error reported is:
ValueError: shapes (2382,61) and (60,) not aligned: 61 (dim 1) != 60 (dim 0)
I assume that in the validation set, one of the features has one value more than in the training set.